人工智能基礎軟件開發(fā)教程(三) 更多有用的Python庫
在人工智能和軟件開發(fā)的實踐中,Python憑借其豐富的庫生態(tài)系統(tǒng)成為了不可或缺的工具。繼前兩章介紹了基本庫后,本章將深入探討更多實用的Python庫,以幫助開發(fā)者高效構建智能應用。這些庫覆蓋數(shù)據(jù)處理、模型訓練、可視化和部署等關鍵環(huán)節(jié)。
一、數(shù)據(jù)處理與增強庫
- Pandas:雖然基礎,但Pandas在數(shù)據(jù)清洗和預處理中至關重要。它提供DataFrame結構,支持靈活的數(shù)據(jù)操作,如合并、過濾和聚合。例如,在訓練模型前,常用Pandas加載CSV文件并處理缺失值。
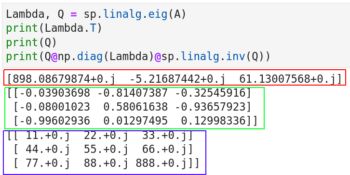
- NumPy:作為科學計算的核心,NumPy支持高效的數(shù)組運算,是許多AI庫(如TensorFlow)的基礎。對于矩陣操作和數(shù)值計算,NumPy可以大幅提升性能。
二、機器學習與深度學習庫
- Scikit-learn:這是一個全面的機器學習庫,適合初學者和專家。它提供了分類、回歸、聚類等算法,以及模型評估工具。例如,使用Scikit-learn可以快速實現(xiàn)一個支持向量機(SVM)模型。
- TensorFlow和PyTorch:這兩個庫是深度學習的領軍者。TensorFlow由Google開發(fā),適合生產(chǎn)環(huán)境;PyTorch由Facebook推出,以其動態(tài)計算圖深受研究人員喜愛。它們支持神經(jīng)網(wǎng)絡構建、訓練和部署,例如用于圖像識別或自然語言處理任務。
- Keras:作為高層API,Keras可以運行在TensorFlow之上,簡化了深度學習模型的開發(fā)。它適合快速原型設計,如用幾行代碼構建一個卷積神經(jīng)網(wǎng)絡。
三、自然語言處理(NLP)庫
- NLTK和spaCy:NLTK是經(jīng)典的NLP庫,提供文本處理工具如分詞和詞性標注;spaCy則更注重性能和工業(yè)應用,支持實體識別和依賴解析。在構建聊天機器人或情感分析系統(tǒng)時,這些庫不可或缺。
- Transformers(由Hugging Face提供):這個庫基于Transformer架構,提供了預訓練模型(如BERT和GPT),可以輕松進行文本生成、翻譯等任務。例如,使用Transformers可以快速部署一個問答系統(tǒng)。
四、計算機視覺庫
- OpenCV:這是一個開源計算機視覺庫,支持圖像和視頻處理。在AI應用中,常用于對象檢測、人臉識別和實時視頻分析。
- Pillow:作為Python圖像處理庫,Pillow適合簡單的圖像操作,如調整大小和格式轉換,常與深度學習模型結合使用。
五、模型部署與優(yōu)化庫
- Flask或FastAPI:這些Web框架用于將AI模型部署為API服務。例如,使用Flask可以創(chuàng)建一個RESTful API,讓用戶通過HTTP請求調用模型預測功能。
- ONNX(Open Neural Network Exchange):這個格式允許模型在不同框架間轉換,提高兼容性和部署效率。
六、實用工具庫
- Jupyter Notebook:雖然不是嚴格意義上的庫,但Jupyter是數(shù)據(jù)科學和AI開發(fā)的標準環(huán)境,支持交互式編碼和可視化。
- Matplotlib和Seaborn:這些庫用于數(shù)據(jù)可視化,幫助分析模型性能和數(shù)據(jù)集分布。
掌握這些Python庫可以顯著提升人工智能軟件開發(fā)的效率。建議初學者從Scikit-learn和Pandas入手,逐步擴展到TensorFlow或PyTorch。在實際項目中,結合具體需求選擇合適的庫,并參考官方文檔和社區(qū)資源,以構建可靠的AI應用。持續(xù)學習和實踐是掌握這些工具的關鍵。
如若轉載,請注明出處:http://m.hnszyyfck.com.cn/product/33.html
更新時間:2026-03-15 23:25:39